1.SUBSTR
문자열의 일부를 추출할때 사용한다.
| 함수 | 설명 |
| SUBSTR(문자열데이터, 시작위치, 추출길이) | 문자열 데이터의 시작 위치부터 추출 길이만큼 추출합니다. 시작 위치가 음수일 경우에는 마지막 위치부터 거슬러 올라간 위치에서 시작합니다. |
| SUBSTR(문자열데이터, 시작위치) | 문자열 데이터의 시작 위치부터 문자열 데이터 끝까지 추출합니다. 시작 위치가 음수일 경우에는 마지막 위치부터 거슬러 올라간 위치에서 끝까지 추출합니다. |
SELECT JOB , SUBSTR(JOB, 1, 2), SUBSTR(JOB, 3, 2),SUBSTR(JOB, 5)
FROM EMPSUBSTR(JOB, 1, 2) = JOB의 1번째 글자에서 두글자 출력
SUBSTR(JOB, 3, 2) = JOB의 3번째 글자에서 두글자 출력
SUBSTR(JOB, 5) = 5번째 글자에서 끝까지 출력
결과값:

시작위치가 음수일 경우~~
SELECT JOB , SUBSTR(JOB, -1, 2), SUBSTR(JOB, -3, 2),SUBSTR(JOB, -5)
FROM EMPSUBSTR(JOB, -1, 2) = JOB의 끝에서 첫번째 글자에서부터 2글자 출력
SUBSTR(JOB, -3, 2) = JOB의 끝에서 세번째 글자에서부터 2글자 출력
SUBSTR(JOB, -5) = 끝에서 5번째 글자에서부터 끝까지 출력
결과값:

SELECT JOB ,
SUBSTR(JOB, -LENGTH(JOB)),
SUBSTR(JOB, -LENGTH(JOB),2),
SUBSTR(JOB, -3, 2)
FROM EMP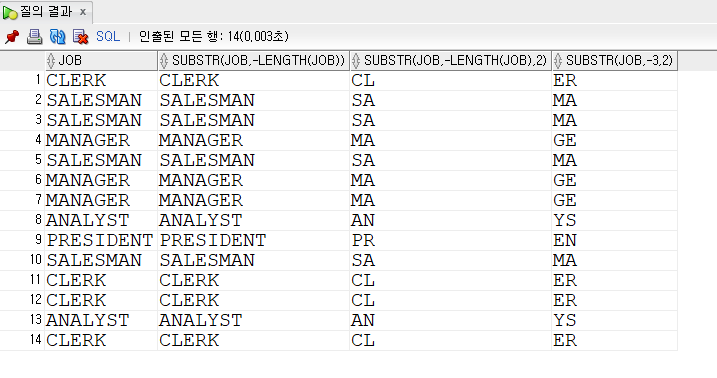
2.INSTR
문자열 데이터 안에서 틀정 문자 위치를 찾을 때 사용한다.
| INSTR( 대상 문자열 데이터, 위치 찾으려는 부분 문자, 위치 찾기 시작할 대상 문자열 데이터 위치(기본값은 1), 시작 위치에서 찾으려는 문자가 몇 번째인지 지정 (기본값은 1) ) |
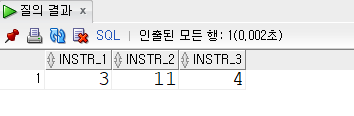
SELECT INSTR('HELLO,ORACLE!', 'L') AS INSTR_1,
INSTR('HELLO,ORACLE!', 'L', 5) AS INSTR_2,
INSTR('HELLO,ORACLE!', 'L', 2, 2) AS INSTR_3
FROM DUAL;SELECT INSTR('HELLO,ORACLE!', 'L') AS INSTR_1, // 'L'이 몇번째 위치에 있느냐~~
INSTR('HELLO,ORACLE!', 'L', 5) AS INSTR_2, // 'L'을 5번째 부터 검색할때, L이 몇번째 위치에 있느냐~~
INSTR('HELLO,ORACLE!', 'L', 2, 2) AS INSTR_3 //'L'을 2번째 부터 검색할 때, 2번째 L의 위치를 찾아라~~
FROM DUAL;
결과값:
SELECT *
FROM EMP
WHERE INSTR(ENAME,'S')>0;SELECT *
FROM EMP
WHERE INSTR(ENAME,'S')>0; // ENAME에서 S가 하나라도 있는것을 찾아라~~
>> 즉, 이것은 LIKE '%S%'와도 같다.
결과값:

3.REPLACE
특정 문자열 데이터에 포함된 문자를 다른 문자로 대체할때 쓰인다.
| REPLACE(문자열 데이터 또는 열이름 , 찾는문자, 대체할 문자) |
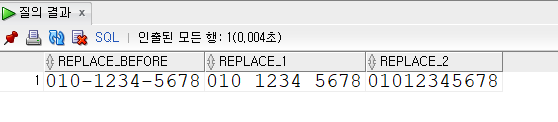
SELECT '010-1234-5678' AS REPLACE_BEFORE,
REPLACE('010-1234-5678','-',' ') AS REPLACE_1,
REPLACE('010-1234-5678','-') AS REPLACE_2
FROM DUAL;>> REPLACE_2 처럼 대체할 문자를 입력하지 않으면 지정한 문자는 문자열 데이터에서 삭제된다.
결과값:
'Practice > Oracle' 카테고리의 다른 글
| SQLD준비_데이터모델링의 이해_속성 (0) | 2022.10.19 |
|---|---|
| SQLD준비_데이터모델링의 이해_엔터티 (0) | 2022.10.19 |
| SQLD 준비_데이터 모델의 이해_3층 스키마 (0) | 2022.10.07 |
| SQLD 준비_데이터 모델의 이해 (0) | 2022.10.06 |
| Oracle_09. IS NULL 연산자 (0) | 2022.10.04 |